
La semana pasada corrí una comparativa completa de clasificación binaria: LightGBM, XGBoost, MLP, Random Forest, SVM, KNN y Árbol de Decisión. Tuneé hiperparámetros con Optuna para cada uno. Cuando terminé de ver la tabla, me di cuenta de algo que no esperaba.
Los números no te dan la respuesta. Te dan las preguntas.
Este artículo no es sobre cuál modelo ganó. Es sobre lo que esa tabla revela cuando la miras con criterio, no solo con métricas.
La tabla que lo generó todo
Siete modelos evaluados sobre el mismo dataset de clasificación binaria. Para cada uno: Accuracy, Precision, Recall, F1-Score, AUC-ROC, Gini, tiempo de búsqueda de hiperparámetros con Optuna (en segundos) y tiempo de entrenamiento final. Los mejores valores de cada columna están marcados con ★. Los valores críticos con △ o ×.
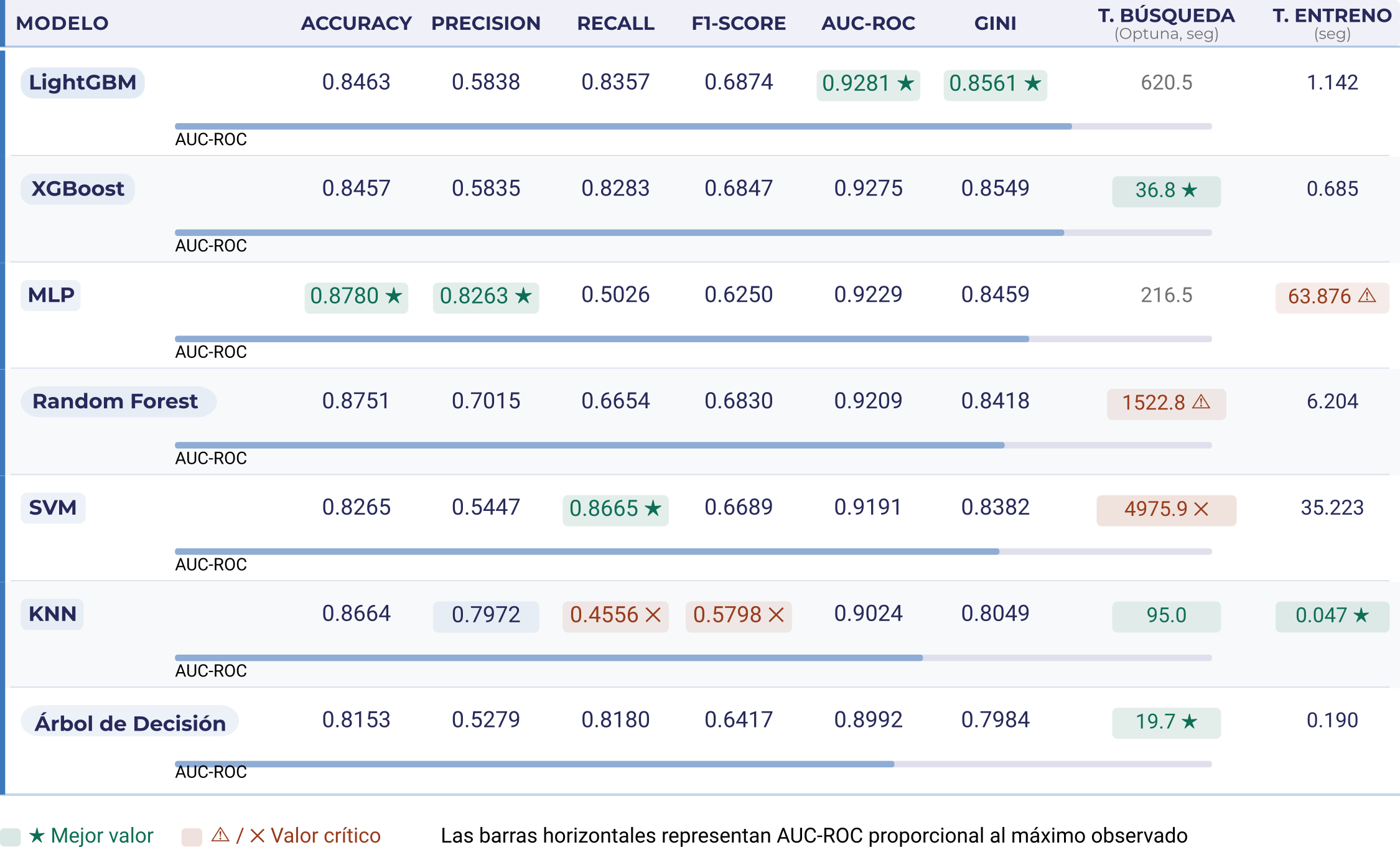
Lo que dicen los números (y lo que no dicen)
Cuatro observaciones. Ninguna dice "usa este modelo". Todas dicen "depende de algo que la tabla no muestra".

LightGBM vs. XGBoost: 0.0006 de AUC-ROC y 583 segundos de diferencia
Una diferencia de 0.0006 en AUC-ROC (0.9281 contra 0.9275) separó al primero del segundo en la métrica principal. LightGBM ganó. Pero XGBoost llegó a ese resultado casi idéntico con 36.8 segundos de búsqueda de hiperparámetros. LightGBM necesitó 620.5.
¿Vale esa diferencia? Depende de una sola variable: ¿con qué frecuencia se reentrenará el modelo? Si el pipeline corre una vez al mes, 10 minutos de diferencia no importan. Si corre diariamente en infraestructura con costos por tiempo de cómputo, esa decisión se convierte en una línea del presupuesto.
La métrica no cambia. El contexto sí.
SVM: el mejor Recall del grupo, al costo más alto
SVM obtuvo el mejor Recall del grupo: 0.8665. En problemas donde el error de falso negativo es el más costoso (detección de fraude, diagnóstico médico, alertas de riesgo crítico), ese número es el que manda. Los otros seis modelos quedaron por debajo.
El problema: 4.975 segundos de búsqueda de hiperparámetros. Casi 83 minutos. En producción, eso no es un detalle técnico, es una restricción operacional real. Un modelo que tarda 83 minutos en optimizarse puede ser completamente inviable en pipelines con ventanas de tiempo ajustadas, aunque tenga el mejor Recall de la comparativa.
Elegir SVM en ese contexto no sería una decisión técnica. Sería una decisión sin considerar las restricciones del sistema.
MLP: mejor Accuracy y Precision, pero ¿quién lee el resultado?
El MLP ganó en dos métricas clave: Accuracy (0.8780) y Precision (0.8263). Y con 216.5 segundos de búsqueda y 63.876 de entrenamiento, los tiempos son razonables para un modelo de red neuronal.
El problema no está en los números. Está en lo que viene después del modelo: ¿quién consume las predicciones? Si el output alimenta un sistema automatizado que solo necesita un número, la caja negra no importa. Si el resultado tiene que ser presentado a un comité, a un regulador, o a un equipo de operaciones que toma decisiones basadas en esa predicción, la explicabilidad deja de ser un lujo técnico y se convierte en un requisito funcional.
Una red neuronal no tiene una regla de decisión que se pueda dibujar en una pizarra. A veces eso es irrelevante. A veces es determinante.
Árbol de Decisión: el AUC más bajo, el argumento más subestimado
El Árbol de Decisión tiene el AUC-ROC más bajo del grupo: 0.8992. También el tiempo de búsqueda más bajo: 19.7 segundos. Y el tiempo de entrenamiento de 0.190 segundos, el más rápido por lejos.
El argumento que nadie hace explícito: es el único modelo de este grupo que puede presentarse como un diagrama de flujo inteligible a alguien sin formación técnica. "Si el ingreso mensual es menor a X y el historial de pagos muestra más de Y atrasos, el resultado es Z." Esa transparencia tiene valor en contextos donde la decisión necesita ser auditada, justificada o explicada.
En ciertos proyectos, 0.03 puntos menos de AUC valen exactamente ese nivel de claridad. En otros, no. Pero el argumento merece estar sobre la mesa antes de descartarlo.
El criterio que falta en la tabla
Hay cuatro variables que ninguna métrica de clasificación captura, pero que pesan igual o más en la decisión final de qué modelo llevar a producción.
Frecuencia de reentrenamiento
Un modelo que se entrena una vez tolera tiempos de búsqueda largos. Un modelo que se reentrenará cada 24 horas en producción no. El tiempo de búsqueda de Optuna no es un número de laboratorio, es un costo operacional que se multiplica con cada ciclo.
Audiencia del resultado
¿Quién toma decisiones basándose en las predicciones? Un sistema automatizado no necesita explicaciones. Un analista de negocio, un auditor o un equipo de operaciones sí. La explicabilidad no es una propiedad técnica del modelo, es una propiedad de la relación entre el modelo y su audiencia.
Costo asimétrico del error
En casi ningún problema real un falso positivo y un falso negativo cuestan lo mismo. Recall vs. Precision no es una discusión teórica sobre métricas, es una pregunta sobre qué tipo de error le duele más a quien depende del modelo. Responderla antes de mirar la tabla cambia completamente qué columna importa.
Infraestructura disponible
Un modelo con 63 segundos de entrenamiento puede ser perfectamente viable en un servidor dedicado e inviable en un ambiente serverless con límite de tiempo de ejecución. Las métricas de rendimiento predictivo son independientes del entorno. Los tiempos de cómputo no.
"Las métricas son una entrada al criterio, no un reemplazo."
Tres preguntas antes de elegir modelo
No un ranking. No un flowchart. Tres preguntas que, respondidas en orden, acotan el espacio de decisión antes de abrir la tabla de métricas.
¿Qué error te cuesta más caro?
Si el falso negativo es más costoso que el falso positivo, optimiza Recall. Si el falso positivo es más costoso, optimiza Precision. Si no puedes permitirte ninguno de los dos, F1. Responder esto antes de ver la tabla elimina la mayoría de los candidatos antes de comparar AUC.
¿Quién consume el output del modelo?
Si el output alimenta un sistema automatizado sin intervención humana, la explicabilidad es opcional. Si el output informa decisiones tomadas por personas, la explicabilidad es un criterio de selección tan válido como el AUC-ROC. Ignorarlo no lo hace desaparecer; aparece después, en la reunión donde nadie entiende por qué el modelo decidió lo que decidió.
¿Cuánto tiempo de cómputo tienes disponible?
Esta pregunta va antes de mirar los tiempos de la tabla, porque define qué modelos son candidatos reales. Si la respuesta es "menos de 60 segundos para búsqueda", SVM queda fuera independientemente de su Recall. Definir las restricciones operacionales primero evita el trabajo de optimizar un modelo que no puede usarse en producción.
Métricas como entrada, no como respuesta
Elegir modelo no es una decisión técnica pura. Es una decisión que integra métricas de rendimiento, restricciones operacionales, audiencia del resultado y costos asimétricos del error. Quien entiende eso no busca el modelo con el AUC más alto, busca el modelo más adecuado para el problema específico que está resolviendo.
La tabla de esta comparativa tiene nueve columnas. Ninguna se llama "contexto de producción". Ninguna se llama "audiencia". Ninguna se llama "costo del error". Y sin embargo, esas tres variables determinan cuál de las siete filas termina en producción.
La próxima vez que veas una tabla de métricas, la primera pregunta no es ¿cuál tiene el AUC más alto? Es ¿qué estoy tratando de no equivocarme?